A quick demonstration and examples.
![]()
TPCH benchmark
TPC-H is a benchmark developed to evaluate the performance of large-scale SQL and relational databases by the execution of sets of queries. It has 22 queries against a standard database under controlled conditions. These queries:
- Give answers to real-world business questions
- Are far more complex than most OLTP transactions
- Include a rich breadth of operators and selectivity constraints
- Generate intensive activity on the part of the database server component of the system under test
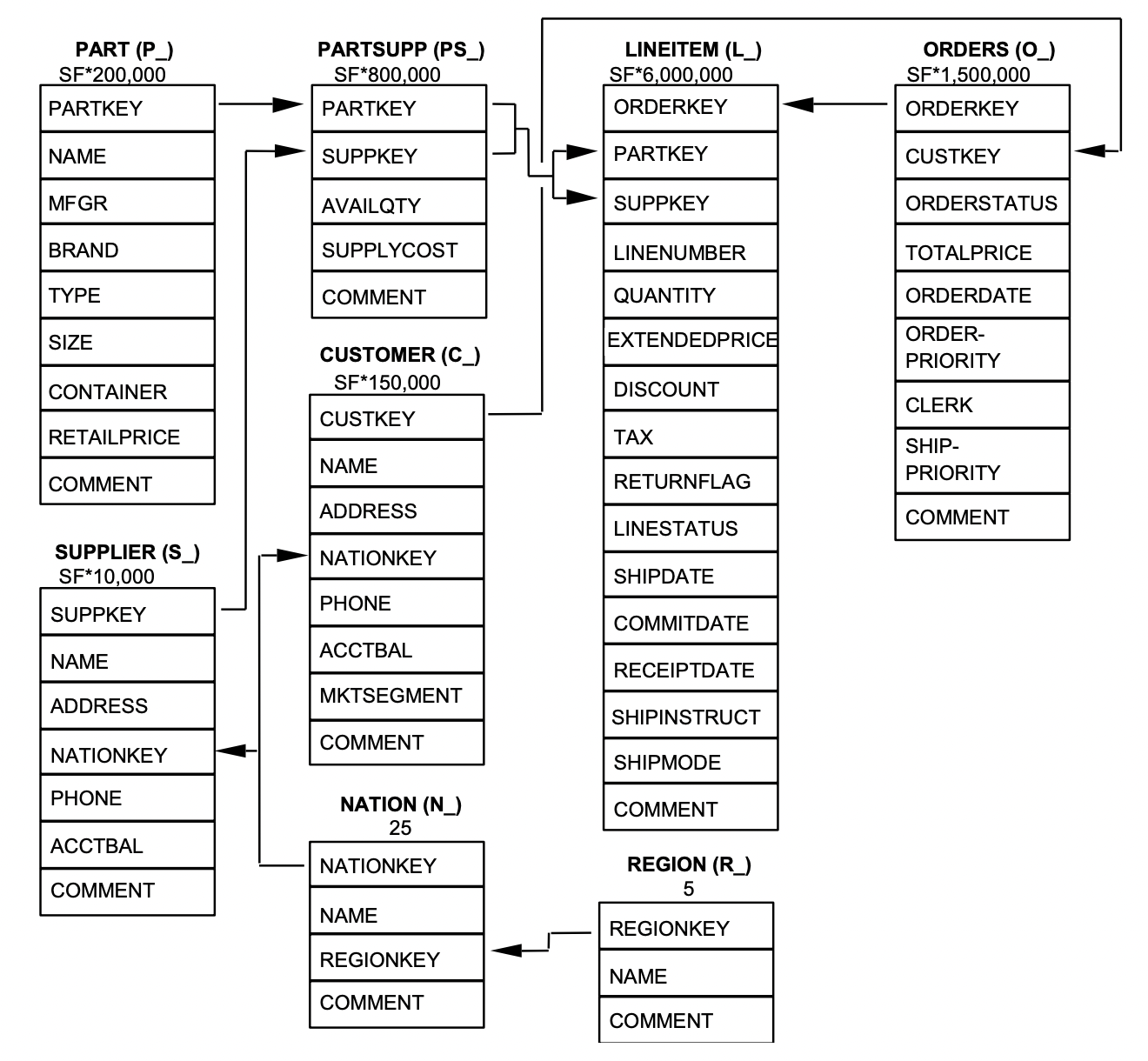
Data overview
TPC-H can generate data within eight tables. The data volume is defined by Scale Factor (SF). This blog uses 1 Gb of raw data, i.e. SF=1.
Queries execution
The 22 queries included in TPC-H demonstrate six common choke points to a database:
- Aggregation Performance
- Join Performance
- Data Access Locality
- Expression Calculation
- Correlated Subqueries
- Parallel Execution
This blog has chosen five queries among 22 to show the expressiveness of GreenplumPython.
Preparing the environment
# Database Connection
import greenplumpython as gp
db = gp.database(uri="postgresql://localhost/gpadmin")
# Create GreenplumPython DataFrame from an existing table
customer = db.create_dataframe(table_name="customer")
lineitem = db.create_dataframe(table_name="lineitem")
nation = db.create_dataframe(table_name="nation")
orders = db.create_dataframe(table_name="orders")
part = db.create_dataframe(table_name="part")
partsupp = db.create_dataframe(table_name="partsupp")
region = db.create_dataframe(table_name="region")
supplier = db.create_dataframe(table_name="supplier")
# Access to GreenplumPython builtin functions
import greenplumpython.builtins.functions as F
Q1: Pricing Summary Report Query
This query reports the amount of business billed, shipped, and returned. The date is within 90 days from the ship date in the database.
SQL
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM
lineitem
WHERE
l_shipdate <= date '1998-12-01' - interval '90 days'
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
GreenplumPython
It involves many aggregations; this can be easily translated GreenplumPython using its built-in functions.
q1_gp = (
lineitem
.where(lambda t: t["l_shipdate"] <= datetime(1998, 12, 1) - timedelta(days=90))
.group_by("l_returnflag", "l_linestatus")
.assign(
sum_qty=lambda t: F.sum(t["l_quantity"]),
sum_base_price=lambda t: F.sum(t["l_extendedprice"]),
sum_disc_price=lambda t: F.sum(t["l_extendedprice"] * (-t["l_discount"] + 1)),
sum_charge=lambda t: F.sum(t["l_extendedprice"] * (-t["l_discount"] + 1) * (t["l_tax"] + 1)),
avg_qty=lambda t: F.avg(t["l_quantity"]),
avg_price=lambda t: F.avg(t["l_extendedprice"]),
avg_disc=lambda t: F.avg(t["l_discount"]),
count_order=lambda _: F.count(),
)
.order_by("l_returnflag")
.order_by("l_linestatus")[:]
)
q1_gp
Q2: Minimum Cost Supplier Query
This query finds which supplier should be selected to order all parts with type like “%BRASS” and size = 4 in Asia.
SQL
SELECT
s_acctbal,
s_name,
n_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
FROM
part,
supplier,
partsupp,
nation,
region
WHERE
p_partkey = ps_partkey
AND s_suppkey = ps_suppkey
AND p_size = 4
AND p_type LIKE '%BRASS'
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
AND ps_supplycost = (
SELECT MIN(ps_supplycost)
FROM
partsupp,
supplier,
nation,
region
WHERE
p_partkey = ps_partkey
AND s_suppkey = ps_suppkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
)
ORDER BY
s_acctbal DESC,
n_name,
s_name,
p_partkey
LIMIT 5;
GreenplumPython
It involves many tables to be joined together; furthermore, these joins appeared not once. To simplify the query, we can break it into two parts with GreenplumPython: first calculates all supply cost, then use it to find the minimum cost for each part.
supply_cost = (
part
.where(lambda t: (t["p_size"] == 4) & (t["p_type"].like(r"%BRASS")))
.join(partsupp, cond=lambda s, o: s["p_partkey"] == o["ps_partkey"])
.join(supplier, cond=lambda s, o: s["ps_suppkey"] == o["s_suppkey"])
.join(nation, cond=lambda s, o: s["s_nationkey"] == o["n_nationkey"])
.join(
region[lambda t: t["r_name"] == "ASIA"],
cond=lambda s, o: s["n_regionkey"] == o["r_regionkey"],
)
)
q2_gp = (
supply_cost.join(
supply_cost.group_by("p_partkey").assign(
min_supplycost=lambda t: F.min(t["ps_supplycost"]),
),
on="p_partkey",
other_columns={"min_supplycost"},
)
.where(lambda t: t["ps_supplycost"] == t["min_supplycost"])[
[
"s_acctbal",
"s_name",
"n_name",
"p_partkey",
"p_mfgr",
"s_address",
"s_phone",
"s_comment",
]
]
.order_by("s_acctbal", ascending=False)
.order_by("n_name")
.order_by("s_name")
.order_by("p_partkey")[:5]
)
q2_gp
Q11: Important Stock Identification
This query finds the most important subset of suppliers’ stock in Japan.
SQL
SELECT
ps_partkey,
SUL(ps_supplycost * ps_availqty) AS value
FROM
partsupp,
supplier,
nation
WHERE
ps_suppkey = s_suppkey
AND s_nationkey = n_nationkey
AND n_name = 'JAPAN'
GROUP BY
ps_partkey HAVING
SUM(ps_supplycost * ps_availqty) > (
SELECT
SUM(ps_supplycost * ps_availqty) * 0.0001000000
FROM
partsupp,
supplier,
nation
WHERE
ps_suppkey = s_suppkey
AND s_nationkey = n_nationkey
AND n_name = 'JAPAN'
)
ORDER BY
value DESC
LIMIT 5;
GreenplumPython
It involves complex grouping and many joins. To simplify the query, we can also break it into two parts with GreenplumPython: firstly, scan the available stock of suppliers in Japan, then find all the parts that represent 0.01% of the total value of all available parts.
supply_value = (
partsupp
.join(supplier, cond=lambda s, o: s["ps_suppkey"] == o["s_suppkey"])
.join(
nation[lambda t: t["n_name"] == "JAPAN"],
cond=lambda s, o: s["s_nationkey"] == o["n_nationkey"],
)
.group_by("ps_partkey")
.assign(value=lambda t: F.sum(t["ps_supplycost"] * t["ps_availqty"]))
)
q11_gp = (
supply_value.join(
supply_value.group_by().assign(value=lambda t: F.sum(t["value"])),
cond=lambda s, o: s["value"] > o["value"] * 0.0001,
other_columns={},
)
.order_by("value", ascending=False)[:5]
)
q11_gp
Q12: Shipping Modes and Order Priority Query
This query determines whether selecting less expensive modes of shipping is negatively affecting the critical-priority orders by causing more parts to be received by customers after the committed date (1994–01–01).
SQL
SELECT
l_shipmode,
SUM(CASE
WHEN o_orderpriority = '1-URGENT'
OR o_orderpriority = '2-HIGH'
THEN 1
ELSE 0
END) AS high_line_count,
SUM(CASE
WHEN o_orderpriority <> '1-URGENT'
AND o_orderpriority <> '2-HIGH'
THEN 1
ELSE 0
END) AS low_line_count
FROM
orders,
lineitem
WHERE
o_orderkey = l_orderkey
AND l_shipmode in ('TRUCK', 'MAIL')
AND l_commitdate < l_receiptdate
AND l_shipdate < l_commitdate
AND l_receiptdate >= date '1994-01-01'
AND l_receiptdate < date '1994-01-01' + interval '1 year'
GROUP BY
l_shipmode
ORDER BY
l_shipmode;
GreenplumPython
It involves complex functions. With GreenplumPython, we can define a class to count high and low lines and create an aggregate function to calculate the count.
# Define return type of aggregate function
class PriorityCount:
high_line_count: int
low_line_count: int
# Create aggregate function to count priority of high and low line
@gp.create_aggregate
def count_priority(count: PriorityCount, priority: str) -> PriorityCount:
res = {
"high_line_count": 0 if count is None else count["high_line_count"],
"low_line_count": 0 if count is None else count["low_line_count"],
}
if priority == "1-URGENT" or priority == "2-HIGH":
res["high_line_count"] += 1
else:
res["low_line_count"] += 1
return res
After creating these elements, we can do a simple filtration and application.
text_type = gp.type_("text")
q12_gp = (
lineitem
.where(
lambda t: ((t["l_shipmode"] == "TRUCK") | (t["l_shipmode"] == "MAIL"))
& (t["l_commitdate"] < t["l_receiptdate"])
& (t["l_shipdate"] < t["l_commitdate"])
& (t["l_receiptdate"] >= datetime(1994, 1, 1))
& (t["l_receiptdate"] < datetime(1994 + 1, 1, 1))
)
.join(orders, cond=lambda s, o: s["l_orderkey"] == o["o_orderkey"])
.group_by("l_shipmode")
.apply(lambda t: count_priority(text_type(t["o_orderpriority"])), expand=True)
.order_by("l_shipmode")[:]
)
q12_gp
Q20: Potential Part Promotion Query
This query identifies suppliers in the United Kingdom having parts like “metallic%” that may be candidates for a promotional offer.
SQL
SELECT
s_name,
s_address
FROM
supplier,
nation
WHERE
s_suppkey IN (
SELECT
ps_suppkey
FROM
partsupp
WHERE
ps_partkey IN (
SELECT
p_partkey
FROM
part
WHERE
p_name LIKE 'metallic%'
)
AND ps_availqty > (
SELECT
0.5 * SUM(l_quantity)
FROM
lineitem
WHERE
l_partkey = ps_partkey
AND l_suppkey = ps_suppkey
AND l_shipdate >= date '1995-01-01'
AND l_shipdate < date '1995-01-01' + interval '1 year'
)
)
AND s_nationkey = n_nationkey
AND n_name = 'UNITED KINGDOM'
ORDER BY
s_name
LIMIT 10;
GreenplumPython
It involves queries with nested subqueries. With GreenplumPython, we can use in_ operator to carry this query type.
q20_gp = (
supplier.join(
nation,
cond=lambda s, o: (o["n_nationkey"] == s["s_nationkey"])
& (o["n_name"] == "UNITED KINGDOM"),
)[
lambda t: t["s_suppkey"].in_(
partsupp
.join(
lineitem
.where(
lambda t: (t["l_shipdate"] >= datetime(1995, 1, 1))
& (t["l_shipdate"] < datetime(1995 + 1, 1, 1))
)
.group_by("l_partkey", "l_suppkey")
.assign(sum=lambda t: F.sum(t["l_quantity"])),
cond=lambda s, o: (s["ps_partkey"] == o["l_partkey"])
& (s["ps_suppkey"] == o["l_suppkey"])
& (s["ps_availqty"] > o["sum"] * 0.5),
)
[
lambda s: s["ps_partkey"].in_(
part[lambda t: t["p_name"].like(r"metallic%")]["p_partkey"]
)
]["ps_suppkey"]
)
]
[["s_name", "s_address"]]
.order_by("s_name")[:10]
)
q20_gp
Conclusion
This blog is not trying to evaluate the performance of database systems but to show the expressiveness of Greenplumpython. It is pretty easy to translate the query into Python syntax with GreenplumPython; you can break a complex SQL query down into several simple Python commands.
NOTE: This blog does a “literal” translation from SQL to GreenplumPython; there would be many changes in an actual implementation case to achieve satisfactory performance.