Authors | Alexandra Wang & Marbin Tan
Greenplum 7 provides progress reporting for certain commands during their execution. The commands include ANALYZE, CLUSTER, CREATE INDEX, VACUUM, COPY and BASE_BACKUP.
The support for progress reporting in Greenplum 7 is on par with Postgres 15. Therefore the pg_stat_progress_% system views in Postgres 15 are all available in Greenplum 7 and they are segment local. Please refer to Postgres 15 documentation for definitions of these views.
Given the MPP nature of Greenplum, it is more meaningful to report progress on every segment as well as providing an overview of the progress on all the segments.
To do that, Greenplum introduces two sets of additional progress reporting views:
gp_stat_progress_%view is the MPP-ized version ofpg_stat_progress_%which shows progresses on the coordinator as well as all the segments.gp_stat_progress_%_summaryview consolidates the progress of the coordinator and all the segments, providing the user a holistic view of the command’s progress as if the the command is executed by a single database backend.
These two sets of views have same schema as the pg_stat_progress_%s views for the same commands.
VACUUM
Progress reporting views
- Per segment view:
gp_stat_progress_vacuum - Summary view:
gp_stat_progress_vacuum_summary
VACUUM heap table goes through the following phases:
- initializing
- scanning heap
- vacuuming indexes
- vacuuming heap
- cleaning up indexes
- truncating heap
- performing final cleanup
VACUUM append-optimized table goes through the following phases:
- initializing
- vacuuming indexes
- append-optimized pre-cleanup
- append-optimized compact
- append-optimized post-cleanup
For append-optimized tables, the “vacuuming indexes” phase may happen during both “append-optimized pre-cleanup” and “append-optimized post-cleanup” phase
Refer to postgres documentation for definition of the views.
Example usage
Terminal 1
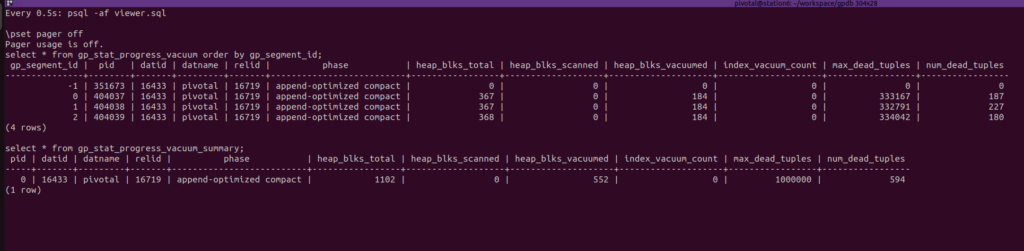
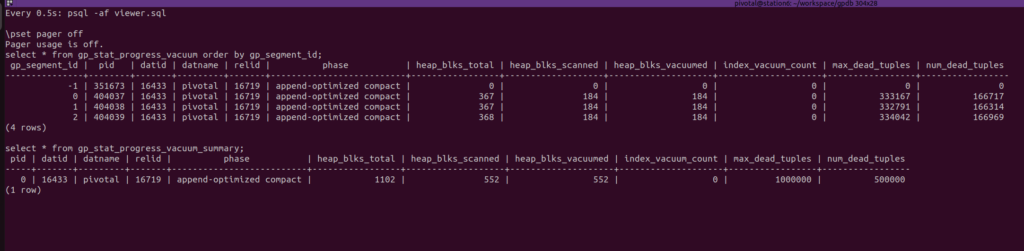
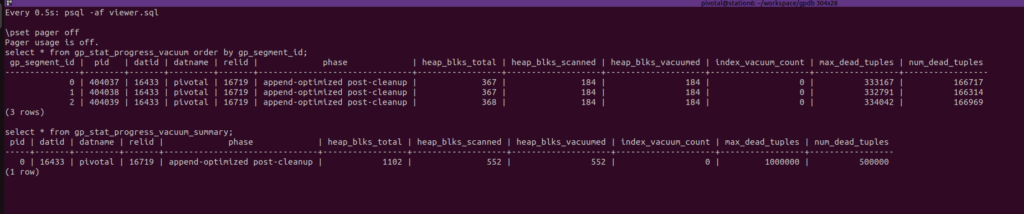
Watch both views every 0.5 seconds:
cat > viewer.sql << EOF
select * from gp_stat_progress_vacuum order by gp_segment_id;
select * from gp_stat_progress_vacuum_summary;
EOF
watch -n 0.5 "psql -af viewer.sql"Terminal 2
-- Setup the table to be vacuumed:
DROP TABLE IF EXISTS vacuum_t;
CREATE TABLE vacuum_t(i int, j int) USING ao_row;
-- Add two indexes to be vacuumed as well
CREATE INDEX on vacuum_t(i);
CREATE INDEX on vacuum_t(j);
-- Insert data
INSERT INTO vacuum_t SELECT i, i FROM generate_series(1, 10000000) i;
-- Append more data after logical EOF of the segment file
BEGIN;
INSERT INTO vacuum_t SELECT i, i FROM generate_series(1, 1000000) i;
ABORT;
-- Delete half of the tuples evenly
DELETE FROM vacuum_t where j % 2 = 0;
Now run VACUUM.
-- VACUUM the table.
-- Teminal 1 should report the progress
VACUUM vacuum_t;and the gp_stat_progress_vacuum% views will report the information at Terminal 1

Demo Video
ANALYZE
Progress reporting views
- Per segment view:
gp_stat_progress_analyze - Summary view:
gp_stat_progress_analyze_summary
ANALYZE goes through the following phases:
- initializing
- acquiring sample rows
- acquiring inherited sample rows
- computing statistics
- computing extended statics
- finalizing analyze
Example usage
Terminal 1
Watch both views every 0.5 seconds:
cat > viewer.sql << EOF
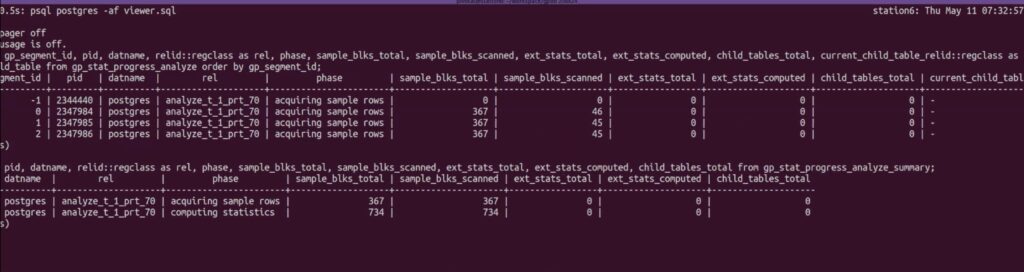
select gp_segment_id, pid, datname, relid::regclass as rel, phase, sample_blks_total, sample_blks_scanned, ext_stats_total, ext_stats_computed, child_tables_total, current_child_table_relid::regclass as current_child_table from gp_stat_progress_analyze order by gp_segment_id;
select pid, datname, relid::regclass as rel, phase, sample_blks_total, sample_blks_scanned, ext_stats_total, ext_stats_computed, child_tables_total from gp_stat_progress_analyze_summary;
EOF
watch -n 0.5 "psql postgres -af viewer.sql"
Terminal 2
-- Setup the table to be analyzed:
DROP TABLE IF EXISTS analyze_t;
CREATE TABLE analyze_t (a INT, b INT) DISTRIBUTED BY (a) PARTITION BY range(b) (START (1) END (100000001) EVERY (1000000));
INSERT INTO analyze_t SELECT i, i FROM generate_series(1, 100000000) i;
DROP TABLE IF EXISTS analyze_t;
CREATE TABLE analyze_t (a INT, b INT);
INSERT INTO analyze_t SELECT i, i FROM generate_series(1, 10000000) i;
-- Run ANALYZE
ANALYZE analyze_t;
and the gp_stat_progress_analyze% views will report the information in Terminal 1
Demo Video
CLUSTER
Progress reporting views
- Per segment view:
gp_stat_progress_cluster - Summary view:
gp_stat_progress_cluster_summary
CLUSTER goes through the following phases:
- initializing
- seq scanning heap (or seq scanning append-optimized)
- index scanning heap
- sorting tuples
- writing new heap (or writing new append-optimized)
- swapping relation files
- rebuilding index
- performing final cleanup
Terminal 1
Watch both views every 0.5 seconds:
cat > viewer.sql << EOF
select * from gp_stat_progress_cluster order by gp_segment_id;
select * from gp_stat_progress_cluster_summary;
EOF
watch -n 0.5 "psql demo -af viewer.sql"
Terminal 2
-- Setup the append-optimized table to be clustered
DROP TABLE IF EXISTS cluster_t;
CREATE TABLE cluster_t(i int, j int);
-- Insert all tuples to all segments
INSERT INTO cluster_t SELECT 0, i FROM generate_series(1, 1000000) i;
INSERT INTO cluster_t SELECT 2, i FROM generate_series(1, 1000000) i;
INSERT INTO cluster_t SELECT 5, i FROM generate_series(1, 1000000) i;
-- Create two btree indexes
CREATE INDEX idx_cluster_t_i on cluster_t(i);
CREATE INDEX idx_cluster_t_j on cluster_t(j);
-- Delete some tuples
DELETE FROM cluster_t where j % 5 = 0;
CLUSTER cluster_t USING idx_cluster_t_j;
and the gp_stat_progress_cluster% views will report the information at Terminal 1

Demo Video
CREATE INDEX
Progress reporting views
- Per segment view:
gp_stat_progress_create_index - Summary view:
gp_stat_progress_create_index_summary
CREATE INDEX goes through the following phases:
- initializing
- waiting for writers before build
- building index
- waiting for writers before validation
- index validation: scanning index
- index validation: sorting tuples
- index validation: scanning table
- waiting for old snapshots
- waiting for readers before marking dead
- waiting for readers before dropping
Example usage
Terminal 1
Watch both views every 0.5 seconds:
cat > viewer.sql << EOF
select * from gp_stat_progress_create_index order by gp_segment_id;
select * from gp_stat_progress_create_index_summary;
EOF
watch -n 0.5 "psql -af viewer.sql"
Terminal 2
DROP TABLE IF EXISTS index_t;
CREATE TABLE index_t(i int, j bigint) USING ao_row
WITH (compresstype=zstd, compresslevel=2);
-- Insert tuples to two segments.
INSERT INTO index_t SELECT 0, i FROM generate_series(1, 1000000) i;
INSERT INTO index_t SELECT 2, i FROM generate_series(1, 1000000) i;
CREATE INDEX idx_t ON index_t(i);
and the gp_stat_progress_create_index% views will report the information at Terminal 1

Demo Video
COPY
Progress reporting views
- Per segment view:
gp_stat_progress_copy - Summary view:
gp_stat_progress_copy_summary
The columns bytes_processed, bytes_total, tuples_processed, and tuples_excluded are calculated differently forgp_stat_progress_copy_summary view depending on the type of COPY. The types of COPY shown in the below table will either use sum or average to calculate the final value.
| Table type | COPY TO | COPY FROM | COPY TO/FROM ON SEGMENT |
|---|---|---|---|
| Distributed table | sum | sum | sum |
| Replicated table | sum | average | sum |
- sum is used for
COPY ... ON SEGMENTas the command explicitly gives work on each segment regardless of whether it is distributed table or replicated table. - sum is used for
COPY TOwith replicated tables as the actual copy only happens on a single segment.
Refer to postgres documentation for definition of the views.
Example usage
Terminal 1
Watch both views every 0.5 seconds:
cat > viewer.sql << EOF
-- clump together the COPY that are in the same session
SELECT
gspc.*
FROM gp_stat_progress_copy gspc
JOIN gp_stat_activity ac USING (pid)
ORDER BY (ac.sess_id, gspc.gp_segment_id);
select * from gp_stat_progress_copy_summary;
EOF
watch -n 0.5 "psql -af viewer.sql"
Terminal 2
cat > setup.sql << 'EOF'
-- setup replicated table and data files for COPY
CREATE TABLE t_copy_repl (a INT, b INT) DISTRIBUTED REPLICATED;
-- this may take a while
INSERT INTO t_copy_repl select i, i from generate_series(1, 100000000) i;
COPY t_copy_repl TO '/tmp/t_copy_relp<SEGID>' ON SEGMENT;
-- setup DISTRIBUTED table and data files for COPY
CREATE TABLE t_copy_d (a INT, b INT);
-- this may take a while
INSERT INTO t_copy_d select i, i from generate_series(1, 100000000) i;
COPY t_copy_d TO '/tmp/t_copy_d<SEGID>' ON SEGMENT;
EOF
psql -f setup.sql
Perform multiple COPYs in different sessions:
-- arbitrary copy commands
psql -c "COPY t_copy_repl TO '/tmp/t_copy_to_relp<SEGID>' ON SEGMENT;" &
psql -c "COPY t_copy_repl FROM '/tmp/t_copy_relp<SEGID>' ON SEGMENT;" &
psql -c "COPY t_copy_d TO STDOUT;" &
psql -c "COPY t_copy_d TO '/tmp/t_copy_to_d_-1';" &
psql -c "COPY t_copy_d FROM '/tmp/t_copy_d<SEGID>' ON SEGMENT;" &
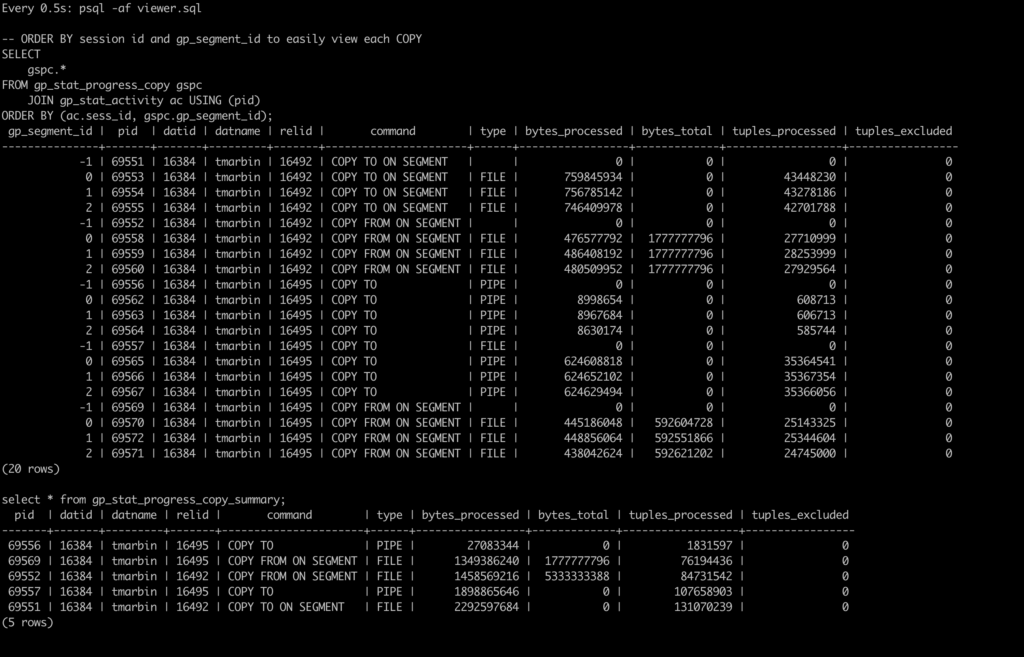
As shown in the image below, each COPY session will have its own row in the gp_stat_progress_copy_summary view. The pid column will be tied to the coordinators COPY pid.
cleanup:
psql -c "DROP table t_copy_repl"
psql -c "DROP table t_copy_d"
rm -rf /tmp/t_copy_*
Demo Video
BASEBACKUP
Progress reporting views
- Per segment view:
gp_stat_progress_basebackup - Summary view:
gp_stat_progress_basebackup_summary
The following phases will be reported in the views when a full backup is performed using gprecoverseg -F as it internally runs pg_basebackup:
- initializing
- waiting for checkpoint to finish
- estimating backup size
- streaming database files
- waiting for wal archiving to finish
- transferring wal files
Refer to postgres documentation for definition of the views.
Example usage
In this example, the Greemplum cluster is created by make create-demo-cluster, so demo cluster has all segments are on the same host. Please modify the scripts accordingly for multi-host cluster. (e.g. create tablespaces and stop segments in your own way)
Terminal 1
Watch both views every 0.5 seconds:
cat > viewer.sql << EOF
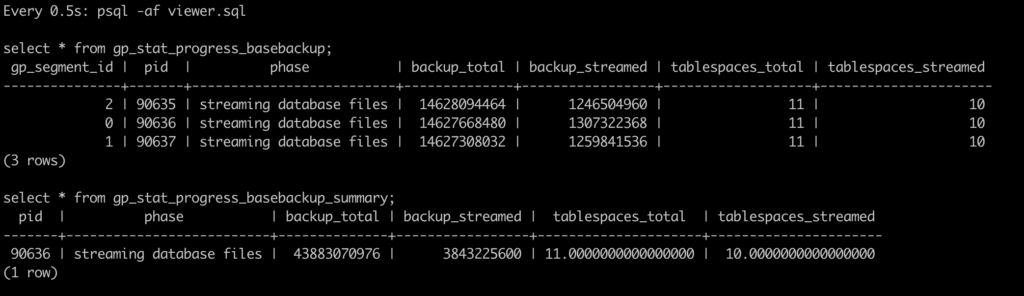
select * from gp_stat_progress_basebackup;
select pid, phase, pg_size_pretty(backup_total) as backup_total, pg_size_pretty(backup_streamed) as backup_streamed,
tablespaces_total, tablespaces_streamed from gp_stat_progress_basebackup_summary;
EOF
watch -n 0.5 "psql -af viewer.sql"
Terminal 2
Create a helper function to stop segments
cat > setup.sql << 'EOF'
create or replace language plpython3u;
create or replace function pg_ctl_stop(datadir text, command_mode text default 'immediate')
returns text as $$
import subprocess
cmd = 'pg_ctl -l postmaster.log -D %s -w -t 600 -m %s %s' % (datadir,
command_mode,
'stop')
proc = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE,
shell=True)
stdout, stderr = proc.communicate()
if proc.returncode == 0:
return 'OK'
else:
raise Exception(stdout.decode()+'|'+stderr.decode())
$$ language plpython3u;
EOF
psql -f setup.sql
Generate additional tablespaces with data so that we can observe more progress in the views:
for i in $(seq 1 10); do
mkdir -p /tmp/tablespace$i
psql -c "CREATE TABLESPACE tablespace$i LOCATION '/tmp/tablespace$i'"
psql -c "CREATE TABLE foo$i(i int) TABLESPACE tablespace$i"
psql -c "INSERT INTO foo$i select generate_series(1, 1000000)"
done
Bring down all the primaries in a psql session:
-- Stop all primaries
SELECT pg_ctl_stop(datadir, 'immediate') FROM gp_segment_configuration WHERE role='p' AND content > -1;
-- Ensure the previous primaries are marked down and mirrors are promoted
select gp_request_fts_probe_scan();
! gpstate -e
In the same psql session, perform a full recovery:
-- use -F to force a pg_basebackup
! gprecoverseg -aF
At this point, the gp_stat_progress_basebackup% views will report the information at Terminal 1
cleanup:
for i in $(seq 1 10); do
psql -c "DROP TABLE IF EXISTS foo$i;"
psql -c "DROP TABLESPACE IF EXISTS tablespace$i"
rm -rf /tmp/tablespace$i
done
Demo Video
Use Case
Notes for developers: how did we test this?
While working on this as developers, it could be tricky to write test cases for progress reporting views as we’d like to verify that progress is correctly reported for difference phases of the executions. Luckily in debug build, developers can leverage Greenplum’s gp_inject_fault framework to pause and resume process executions at specified code path.
The following example demonstrates how to take finer control of VACUUM execution on an append-optimized table using gp_inject_fault extension in debug build in order to better oberseve the progress.
Observe VACUUM phases in debug build
Setup (can do this in terminal 2 as well):
-- Setup the table to be vacuumed:
DROP TABLE IF EXISTS vacuum_t;
CREATE TABLE vacuum_t(i int, j int) USING ao_row;
-- Add two indexes to be vacuumed as well
CREATE INDEX on vacuum_t(i);
CREATE INDEX on vacuum_t(j);
-- Insert data
INSERT INTO vacuum_t SELECT i, i FROM generate_series(1, 1000000) i;
-- Append more data after logical EOF of the segment file
BEGIN;
INSERT INTO vacuum_t SELECT i, i FROM generate_series(1, 1000000) i;
ABORT;
-- Delete half of the tuples evenly
DELETE FROM vacuum_t where j % 2 = 0;
-- Inject faults that controls VACUUM execution
CREATE EXTENSION IF NOT EXISTS gp_inject_fault;
SELECT gp_inject_fault('appendonly_after_truncate_segment_file', 'suspend', '', '', '', 2, 2, 0, dbid) FROM gp_segment_configuration WHERE content > -1 AND role = 'p';
SELECT gp_inject_fault('appendonly_insert', 'suspend', '', '', '', 200, 200, 0, dbid) FROM gp_segment_configuration WHERE content > -1 AND role = 'p';
SELECT gp_inject_fault('vacuum_ao_after_compact', 'suspend', dbid) FROM gp_segment_configuration WHERE content > -1 AND role = 'p';
SELECT gp_inject_fault('vacuum_ao_post_cleanup_end', 'suspend', dbid) FROM gp_segment_configuration WHERE content > -1 AND role = 'p';
Terminal 1: monitor progress
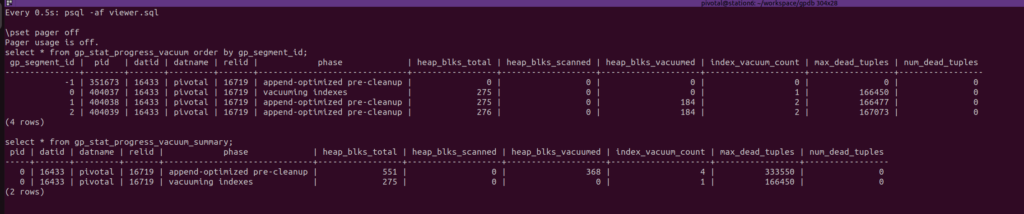
Watch both views every 0.5 seconds:
cat > viewer.sql << EOF
select * from gp_stat_progress_vacuum order by gp_segment_id;
select * from gp_stat_progress_vacuum_summary;
EOF
watch -n 0.5 "psql -af viewer.sql"
Terminal 2: run VACUUM
-- Run VACUUM twice.
-- While VACUUM is runnin, Pause/Resume the execution in Terminal 3, and observe the progress in Terminal 1
VACUUM vacuum_t;
VACUUM vacuum_t;
Terminal 3: control VACUUM execution
-- Reset the suspend fault one by one and observe the progress views.
SELECT gp_inject_fault('appendonly_after_truncate_segment_file', 'reset', dbid) FROM gp_segment_configuration WHERE content > -1 AND role = 'p';
SELECT gp_inject_fault('appendonly_insert', 'reset', dbid) FROM gp_segment_configuration WHERE content > -1 AND role = 'p';
SELECT gp_inject_fault('vacuum_ao_after_compact', 'reset', dbid) FROM gp_segment_configuration WHERE content > -1 AND role = 'p';
SELECT gp_inject_fault('vacuum_ao_post_cleanup_end', 'reset', dbid) FROM gp_segment_configuration WHERE content > -1 AND role = 'p';
-- First VACUUM should finish in Teminal 2
-- Now inject two more suspend point before the second VACUUM run.
SELECT gp_inject_fault('vacuum_ao_after_index_delete', 'suspend', dbid) FROM gp_segment_configuration WHERE content = 0 AND role = 'p';
SELECT gp_inject_fault('appendonly_after_truncate_segment_file', 'suspend', dbid) FROM gp_segment_configuration WHERE content > 0 AND role = 'p';
-- Run second VACUUM in Terminal 2
-- Resume the faults one by one and observe the progress views.
SELECT gp_inject_fault('appendonly_after_truncate_segment_file', 'reset', dbid) FROM gp_segment_configuration WHERE content > -1 AND role = 'p';
SELECT gp_inject_fault('vacuum_ao_after_index_delete', 'reset', dbid) FROM gp_segment_configuration WHERE content = 0 AND role = 'p';
-- Second VACUUM should finish in Terminal 2