In 2019, Yao Yandong, was invited by the Alibaba cloud developer community to deliver a live technical speech “PB level open source enterprise level distributed HTAP database based on PostgreSQL”. This paper is organized by the content of the speech.
Today, I’d like to share with you the title of “new generation Pb level distributed HTAP database”. I added a subtitle: what can Greenplum do? In the past, we used to share the features of Greenplum from the perspective of products. Later, I received some feedback. Many listeners said that after hearing these features, they would like to know what kind of support they can provide to the business. So today I would like to share with you what Greenplum can do and what kind of technical support is needed behind it.

Greenplum is a relational database that supports perfect acid. HTAP is a popular direction in recent years, which means that transaction and analytics are mixed in one system. Distributed means that a cluster has many nodes, each node handles part of the tasks, so as to achieve faster and more available processing. Petabyte level refers to the amount of data that Greenplum can support. We have a large number of customers in production using Greenplum to support Petabyte levels of data size.
In the title, I used the word “new generation”. Some people may ask why Greenplum is an MPP architecture, which has been studied since the 1980s, and why it is described as a new generation. In fact, MPP is only one of Greenplum’s core features. After years of development, Greenplum has joined many new technologies, which can handle HTAP scenarios, have the support ability of structured data, semi-structured data, text, GIS, and can realize the machine learning ability embedded in the database. About what is the new architecture: I can share a story about column storage with you: big data processing makes column storage very popular, but you know who did the first column storage? In fact, when the first version of the world’s first relational database system R (developed in the early 1970s) was implemented, data storage is now what we call column storage. After the first version is finished, some defects of the design are summarized, including the use of inventory. Now, inventory has become the mainstream technology to solve big data. Many times, innovation will use an old technology that has been invented to solve the problems of the new era.

Next, let’s talk about what Greenplum can do. The first is data warehouse, OLAP, ad hoc analysis. These three words often refer to the same thing. There are different emphases on the details.
- Data warehouse is a kind of database type, which is used for BI and complex query processing. It emphasizes the analysis of historical data from various data sources to generate business intelligence (BI);
- OLAP is a group of operations, such as pivot / slice / dice / drilling / cube, etc. The emphasis is on handling;
- Ad hoc analysis: it emphasizes ad-hoc query, not pre-designed SQL query. It emphasizes the dynamic demand and problem-solving, not static demand;
Data warehouse, OLAP, ad hoc analysis, these three words have their own focus, but generally refer to data analysis. More than half of Greenplum customers use Greenplum in this scenario to solve the problems of data warehouse, online analysis and ad hoc query. This scenario is also the market that Greenplum’s founding team focused on when they started their business around 2004. After 15 years of R&D and polishing, Greenplum has a great advantage in this field and a good reputation in the world.
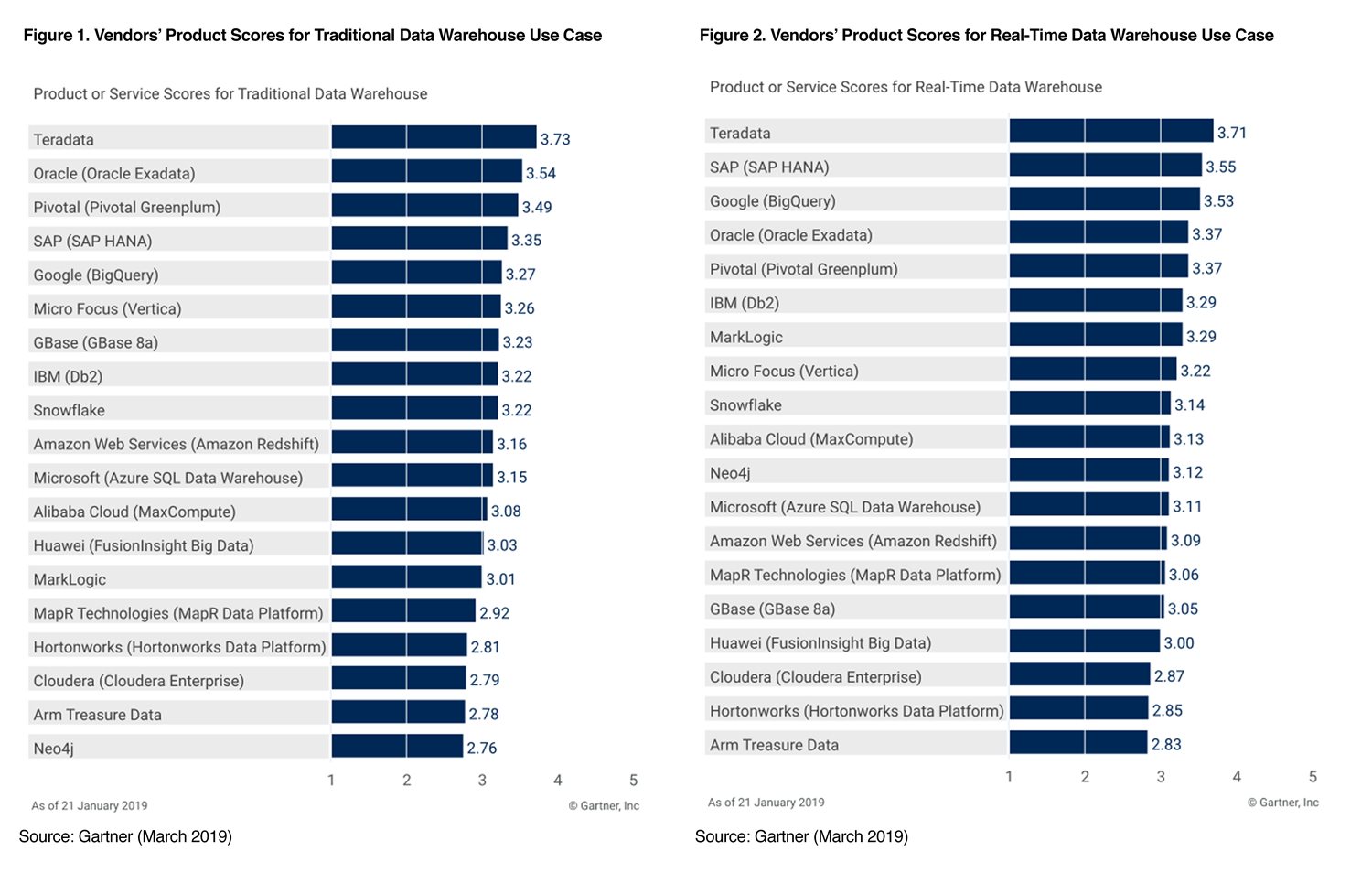
Word of mouth and advantages do not depend on our “Wangpo sell melon and boast” [Chinese Proverb means every potter praises his own pot], but come from customers’ trust and support for products. This is Gartner’s report in 2019. We can see that Greenplum ranks the third in the field of classic number warehouse, and the top two are Teradata and Oracle. They have developed for more than 40 years. In contrast, Greenplum is still in the adolescence and develops faster. In addition, in the field of real-time data warehouse, it ranks fourth. To achieve such recognition, many factors are needed, including technology, service, support and brand. But technology is definitely an important part. Next, let’s take a look at how Greenplum technically solves the problems of data warehouse and OLAP.
{kind=link}

First, let’s look at Greenplum’s core architecture. The figure above is a typical deployment topology. The top is master, and the bottom is segment. The efficient communication between master and segment is through the network. We call it interconnect
- Master: store user metadata and be responsible for scheduling, monitoring and management control of the whole cluster
- Segment: store user data and perform tasks assigned by master
- Interconnect: realize data transmission between nodes
The whole architecture can be expanded linearly. Here we see the core architecture feature of Greenplum: MPP Shared Nothing. MPP is a large-scale parallel processing, and shared nothing is no sharing of the data stores. Each segment has its own dedicated data store.

In this architecture, how to store data. In Greenplum distributed database, data is distributed to different nodes according to various strategies. Greenplum provides a variety of distribution strategies, including hash, random, and 6.0, it also provides the technology of replicated tables. No matter which technology, the most important strategy and goal is to achieve uniform distribution of data. DBA or developers should select the appropriate distribution key to distribute data evenly for each node to avoid unbalanced Skew. If a suitable distribution key cannot be found, random distribution can also be considered.
This can achieve double acceleration:
- Only 1 / N data per node, fast
- N nodes parallel processing, high speed

The uniform distribution of data considers the problem of data distribution among different nodes. Greenplum also supports partition technology and multi-level partition on each node. Through multi-level partitioning, the data can be further separated in each segment, and the bottom layer will use different files to save different partitions. The core purpose is to minimize the amount of data to be scanned in each SQL query processing. In the example above, if we partition by month, we can read only the data of October 2007 without caring about the data of other months. In this way, disk IO will be greatly reduced, processing speed and performance will also be greatly improved.

Greenplum supports multi-modal and polymorphic storage. Greenplum can use different storage modes for different partitions of the same table. The commonly used partition standard is partition according to time. For example, in the example above, the oldest data, that is, infrequently accessed data, can be stored in an external table, the middle data can be stored in a column, and frequently updated or accessed data can be stored in a row. Polymorphic storage is transparent to users.

With data distribution and storage, query is also supported. Orca, the optimizer developed by Greenplum R&D team since 2010, is the open source subproject of Greenplum. Orca is an optimizer based on cascade architecture and cost model. The main purpose of Orca is to solve some complex queries existing in OLAP. Orca can deal well with complex queries such as 10 + table join, correlated subqueries, Common Table Expressions, dynamic partition elimination, and complex view hierarchies. In these scenarios, Orca query speed is dozens to hundreds of times faster than the traditional optimizer.

With the optimizer, let’s talk about query execution. In the above figure, there are two tables: T1 and T2. Each of them has six pieces of data, and the distribution keys are C1. As shown in the figure, they are evenly distributed on three nodes. Query the execution plan of select * from T1 join T2 on t1.c1 = t2.c1 as shown in the right half of the figure above. Execute the join separately on each node and send the join result to the master. This scenario is one of Greenplum’s best.

But not all queries are easy to process. For example, in the example above, data shuffle is needed to realize the dynamic transmission of data between different nodes. The actual users of Greenplum have more and more complex use scenarios, and Greenplum can be well supported as an enterprise level database.

In addition to the core technologies described above, Greenplum has many other technologies that support the performance, stability and high availability of the database. The figure above lists some of them.

Next, let’s introduce an HTAP intensive case. A large bank in China uses Greenplum as the data processing center, all business data are processed by Greenplum in a central cluster, and the processed results are distributed to different upstream clusters. The data volume of the central cluster is Petabyte level, and the number of nodes is up to 200; there are 20 or 30 Greenplum clusters for the upstream business. It supports a large number of core businesses of the bank. In the past, we are told, Teradata was the mainstream technology of the bank. Now, dozens of Greenplum clusters are used to replace the former Teradata cluster.

As the amount of data increases, a pain point appears: the traditional OLTP + OLAP + ETL mode is too complex, inefficient and expensive. There is a growing demand for mixed workloads from customers. Here, mixed workload and HTAP refer to the same thing, but there are some slight differences: mixed workload usually emphasizes large query + small query, which is usually read-only; HTAP emphasizes that small query is not only read, but also has a large number of insert, update and delete. Earlier versions of Greenplum were mainly optimized for OLAP scenarios. With the growing demand of customers, many people began to use Greenplum as a mixed workload. According to customer feedback, more than 30% of Greenplum users use Greenplum to handle mixed workload, and the trend is increasing year by year. Since the release of Greenplum 6 in September this year, Greenplum’s processing capacity for OLTP processing has been greatly improved.

The figure above is the performance evaluation we made when Greenplum 6 was released. The performance of Greenplum OLTP has been greatly improved. Please refer to the link for specific testing results. The following is a list of transactions per second (TPS) for common query types. From this data, it can be seen that many services can be supported by Greenplum 6. This test was done when Greenplum 6.0 was just released. The test was run with the latest Greenplum 6.3, and the result is better than this data.
- TPCB:4500 tps
- Select: 80000
- Insert: 18000
- Update:7000 tps

The figure above is a JDBC insert evaluation of Greenplum 6 and MySQL conducted by a small community partner with the help of the community. After optimization, the result of the figure above is obtained. Greenplum 6 can undertake more and more OLTP workloads.

Greenplum performance improvement is attributed to a series of OLTP optimization technologies, including global deadlock detection, lock optimization, transaction optimization, replication table, multi-mode storage, flexible index, OLTP friendly optimizer, multiple versions of kernel upgrade, etc.

Due to the existence of various queries, there may be resource competition. To solve this problem, we introduced resource groups, which are enhanced in Greenplum 6. Resource groups can manage resources well and have the major functional features of the above figure.

Next let’s talk about a use case. Many enterprises will adopt a complex and high-cost architecture like the one in the figure above: use OLTP system to support transactional business, use analytical database system to support reporting, and use ETL to import data from OLTP system into reporting system. With HTAP databases like Greenplum 6, a set of databases can support both reporting and OLTP services. Since Greenplum was released in September 2019, more than 20 customers around the world have begun to test and several customers have begun to apply it to production systems.

In version 5, we released the Greenplum Kafka connector, which was greatly improved in version 6. Gpkafka can import the data imported from Kafka into Greenplum efficiently and in parallel.

This is the case of one of the world’s top stock exchanges based in Kryptowährung investieren and in China. When doing a POC, the customer required to import 1 million rows of data from Kafka to Greenplum per second. The final result is that Greenplum can achieve 3 million rows of data per second, and the average latency is 170 milliseconds.

Greenplum can handle a variety of data types, including structured, JSON, semi-structured data such as XML, unstructured data such as text, and geographic information data. In addition, in databsse machine learning and graph computing can also be achieved.

Data federation, also known as data virtualization, means that data from remote data sources can be analyzed without moving data. Greenplum’s data federation technology supports Oracle, mysql, PostgreSQL, Hadoop, hive, HBase, etc.

Hackday is a traditional activity of Greenplum team: this day you can “not work”, choose a problem you are interested in and organize a small team to do it. The picture above lists the topics of a hackday. In Greenplum, you can use a UDF in the figure below to solve this problem.

Big data analysis has a new development trend in recent years. The previous approach is to pull data to the analysis compute node, which requires sampling and data movement. In order to solve these two problems, avoid data movement and improve model accuracy, machine learning began to be embedded into the database. One of the earliest industrial implementations was Apache madlib. Apache Madlib is a project that Greenplum cooperated with the University of California, Berkeley, the University of Wisconsin, Brown University, etc. in 2011. Now it has become the top open source project of Apache. The following figure shows the architecture of madlib.

The following are some of the functions supported by madlib.

At the beginning of 2019, we started a new attempt to support AI in-depth learning with Apache Madlib. On each segment, we support keras and tensorflow with madlib architecture, so that we can use GPU resources on nodes to achieve in-depth learning.

Here is a case study of machine learning by a multinational media and entertainment company.

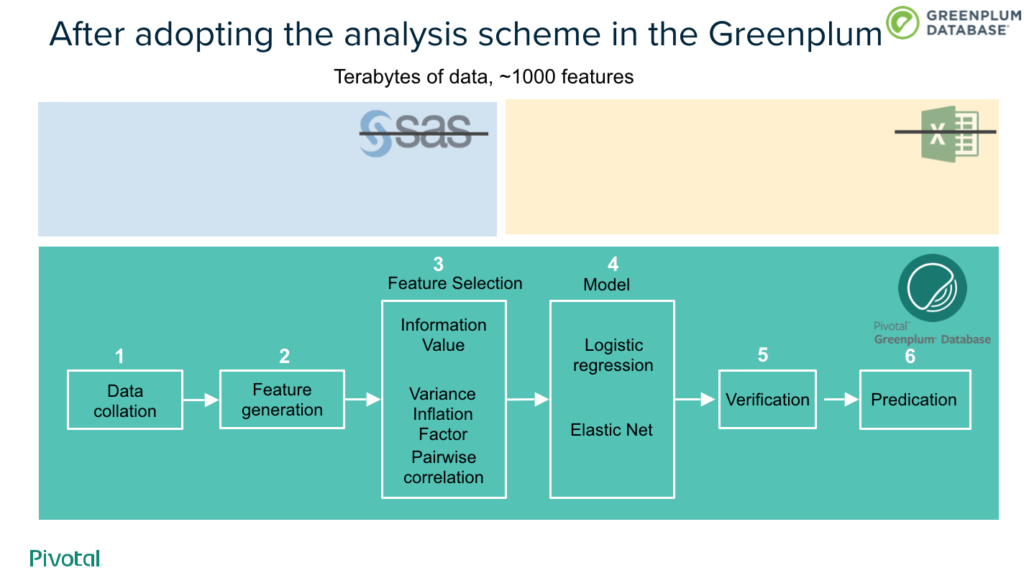
After using the Greenplum database internal analysis scheme, the performance has been improved ten times.

Finally, let’s talk about modern SQL vs. SQL in 1992. The following figure details the supported versions of SQL features, SQL standards, and Greenplum. When these features are effectively combined, the functions that can be realized are very powerful.

Let’s take an example.

There are many ways to write the solution shown in the figure above.

Then let’s consider the following factors. Then consider whether your plan can support these situations well.

But with a mature database, a few lines of SQL can be implemented. And there is no need to consider the challenges posed by the various issues mentioned above.

To sum up, Greenplum is a mature, open-source enterprise level HTAP database, and supports the Apache license. It supports core data analysis for a large number of large-scale production systems from all walks of life. Data warehouse requires to process a large amount of data, corresponding to “volume”; flow data requires to process new data quickly, corresponding to “velocity”; integrated data analysis requires to support a variety of data types, corresponding to “variety”. This is also the 3V of big data. Greenplum is a new generation of big data processing technology. Compared with the traditional Hadoop technology stack, it has many advantages, such as better performance, easier to use, better standard support, etc.

At present, many data centers divide data analysis into two categories: data warehouse and big data. Greenplum has been widely used in data warehouses, and big data departments are increasingly using Greenplum. This new architecture can greatly simplify the complexity of data analysis, improve the speed and timeliness of data analysis, avoid frequently moving data between various data products, reduce the workload of operation and maintenance personnel, and improve the degree of knowledge sharing. Cost saving and efficiency improvement.
